Hi!
I made a coplanar face merging function that takes your favorite cubic extracted mesh and simplifies it leaving an average of 17% of the poly count.
This helps a lot both when rendering and when serializing the mesh to a file (So the mesh extractor doesn't slow things down).
As examples, I have this pics to show you:
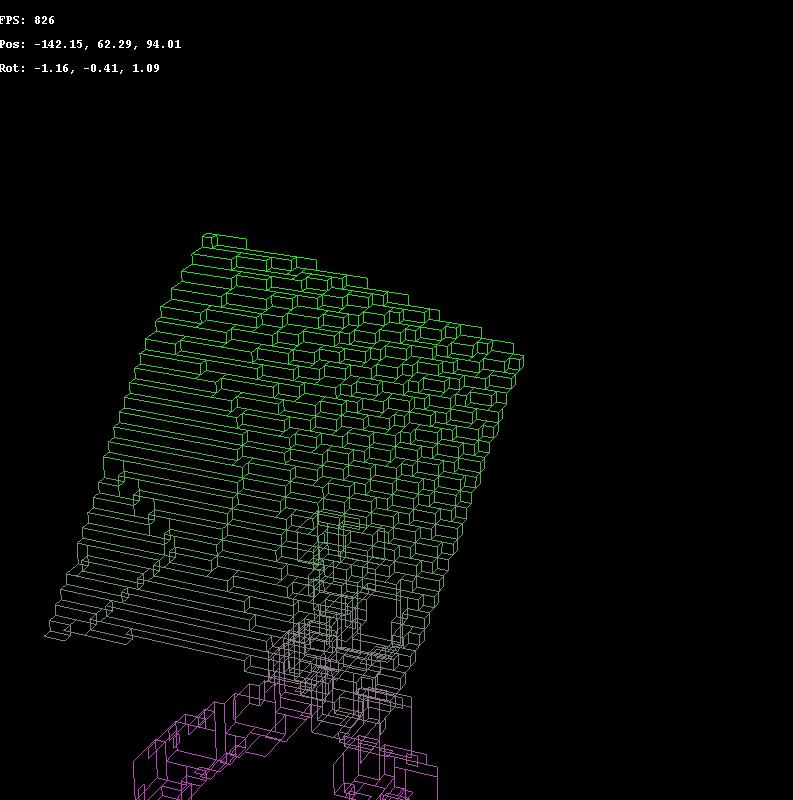
This mesh here was composed of 3120 triangles, now it's made of 501 quads. (16% ratio)
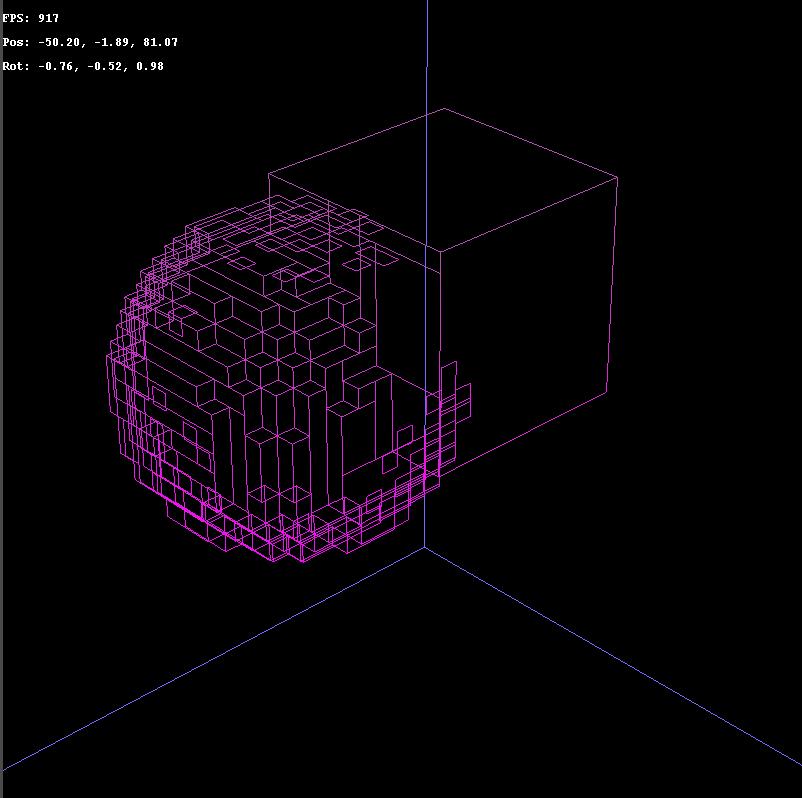
This other mesh was composed of 5274 triangles, now it's made of 947 quads. (17% ratio)
I know that comparing tris with quads is unfair, but it's still a great way to minimize game data (And lighting fast, 2 seconds to merge 5000 quads).
Well, here's the code for you all =D
Please note that, while you'll still be using the vertex data in the surface mesh, the indices are now filling a vector<Quad>.
Also, I'm using PositionMaterialNormal vertexType. Sorry
DoCoplanarMerge returns the number of successful merging operations done in that pass. I call it until no more merging can be done
.h
Code:
struct Quad
{
uint32_t s_idx[4];
};
vector<Quad> c_quads;
void OptimizeMesh(void);
int DoCoplanarMerge(void);
{
uint32_t s_idx[4];
};
vector<Quad> c_quads;
void OptimizeMesh(void);
int DoCoplanarMerge(void);
.cpp
Code:
void PolyvoxModel::OptimizeMesh(void){
const vector<uint32_t>& vecIndices = c_surfaceMesh->getIndices();
const vector<PolyVox::PositionMaterialNormal>& vecVertices = c_surfaceMesh->getVertices();
// FOR EVERY TWO TRIS, MAKE A QUAD
for(uint32_t l_triWalk = 0; l_triWalk < vecIndices.size(); l_triWalk += 6)
{
uint32_t l_triA = l_triWalk;
uint32_t l_triB = l_triWalk + 3;
if ((vecIndices[l_triA + 1] == vecIndices[l_triB]) &&
(vecIndices[l_triA + 2] == vecIndices[l_triB + 2]))
{
Quad l_newQuad;
l_newQuad.s_idx[0] = vecIndices[l_triA];
l_newQuad.s_idx[1] = vecIndices[l_triA + 1];
l_newQuad.s_idx[2] = vecIndices[l_triB + 1];
l_newQuad.s_idx[3] = vecIndices[l_triA + 2];
c_quads.push_back(l_newQuad);
}
else if ( (vecIndices[l_triA + 1] == vecIndices[l_triB + 1]) &&
(vecIndices[l_triA + 2] == vecIndices[l_triB]))
{
Quad l_newQuad;
l_newQuad.s_idx[0] = vecIndices[l_triA];
l_newQuad.s_idx[1] = vecIndices[l_triA + 1];
l_newQuad.s_idx[2] = vecIndices[l_triB + 2];
l_newQuad.s_idx[3] = vecIndices[l_triA + 2];
c_quads.push_back(l_newQuad);
}
}
int l_totalMerges = 0;
int l_passMerges = 0;
do{
l_passMerges = DoCoplanarMerge();
l_totalMerges += l_passMerges;
} while(l_passMerges);
PrepareOptimizedDisplayList();
}
int PolyvoxModel::DoCoplanarMerge(void){
const vector<PolyVox::PositionMaterialNormal>& vecVertices = c_surfaceMesh->getVertices();
// MERGE ADYACENT QUADS
vector<Quad> l_quadsByPlane[6];
enum{
eUp, eDown, eLeft, eRight, eForward, eBackward, ePlaneCount
};
for (int l_quadWalk = 0; l_quadWalk < c_quads.size(); l_quadWalk++){
PolyVox::Vector3DFloat l_normal = vecVertices[c_quads[l_quadWalk].s_idx[0]].getNormal();
if (l_normal.getX() == 1) l_quadsByPlane[eRight].push_back(c_quads[l_quadWalk]);
else if (l_normal.getX() == -1) l_quadsByPlane[eLeft].push_back(c_quads[l_quadWalk]);
else if (l_normal.getY() == 1) l_quadsByPlane[eUp].push_back(c_quads[l_quadWalk]);
else if (l_normal.getY() == -1) l_quadsByPlane[eDown].push_back(c_quads[l_quadWalk]);
else if (l_normal.getZ() == 1) l_quadsByPlane[eForward].push_back(c_quads[l_quadWalk]);
else if (l_normal.getZ() == -1) l_quadsByPlane[eBackward].push_back(c_quads[l_quadWalk]);
}
c_quads.clear();
// CHECK IF ANY TWO QUADS SHARE TWO VERTICES, MERGE THEM!
int l_mergedQuads = 0;
for (int l_planeWalk = 0; l_planeWalk < ePlaneCount; l_planeWalk++){
bool* l_alreadyMerged = new bool[l_quadsByPlane[l_planeWalk].size()];
memset(l_alreadyMerged, 0, l_quadsByPlane[l_planeWalk].size());
// MERGE AND PUSH ADJACENT QUADS
for (int l_currentQuadWalk = 0; l_currentQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_currentQuadWalk++){
if (l_alreadyMerged[l_currentQuadWalk]) continue;
Quad l_currentQuad = l_quadsByPlane[l_planeWalk][l_currentQuadWalk];
PolyVox::Vector3DFloat l_currentPos[4];
for (int l_vWalk = 0; l_vWalk < 4; l_vWalk++){
l_currentPos[l_vWalk] = vecVertices[l_currentQuad.s_idx[l_vWalk]].getPosition();
}
for (int l_compareQuadWalk = 0; l_compareQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_compareQuadWalk++){
if (l_currentQuadWalk == l_compareQuadWalk) continue;
if (l_alreadyMerged[l_currentQuadWalk]) break;
if (l_alreadyMerged[l_compareQuadWalk]) continue;
Quad l_compareQuad = l_quadsByPlane[l_planeWalk][l_compareQuadWalk];
PolyVox::Vector3DFloat l_comparePos[4];
for (int l_vWalk = 0; l_vWalk < 4; l_vWalk++){
l_comparePos[l_vWalk] = vecVertices[l_compareQuad.s_idx[l_vWalk]].getPosition();
}
if ((l_currentPos[2] == l_comparePos[1]) &&
(l_currentPos[3] == l_comparePos[0])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_currentQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_currentQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_compareQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_compareQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[1] == l_comparePos[0]) &&
(l_currentPos[2] == l_comparePos[3])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_currentQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_compareQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_compareQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_currentQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[0] == l_comparePos[3]) &&
(l_currentPos[1] == l_comparePos[2])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_compareQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_compareQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_currentQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_currentQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[0] == l_comparePos[1]) &&
(l_currentPos[3] == l_comparePos[2])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_compareQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_currentQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_currentQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_compareQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
}
}
// PUSH LONELY QUADS
for (int l_currentQuadWalk = 0; l_currentQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_currentQuadWalk++){
if (!l_alreadyMerged[l_currentQuadWalk]){
c_quads.push_back(l_quadsByPlane[l_planeWalk][l_currentQuadWalk]);
}
else{
l_mergedQuads++;
}
}
delete[] l_alreadyMerged;
}
return l_mergedQuads;
}
const vector<uint32_t>& vecIndices = c_surfaceMesh->getIndices();
const vector<PolyVox::PositionMaterialNormal>& vecVertices = c_surfaceMesh->getVertices();
// FOR EVERY TWO TRIS, MAKE A QUAD
for(uint32_t l_triWalk = 0; l_triWalk < vecIndices.size(); l_triWalk += 6)
{
uint32_t l_triA = l_triWalk;
uint32_t l_triB = l_triWalk + 3;
if ((vecIndices[l_triA + 1] == vecIndices[l_triB]) &&
(vecIndices[l_triA + 2] == vecIndices[l_triB + 2]))
{
Quad l_newQuad;
l_newQuad.s_idx[0] = vecIndices[l_triA];
l_newQuad.s_idx[1] = vecIndices[l_triA + 1];
l_newQuad.s_idx[2] = vecIndices[l_triB + 1];
l_newQuad.s_idx[3] = vecIndices[l_triA + 2];
c_quads.push_back(l_newQuad);
}
else if ( (vecIndices[l_triA + 1] == vecIndices[l_triB + 1]) &&
(vecIndices[l_triA + 2] == vecIndices[l_triB]))
{
Quad l_newQuad;
l_newQuad.s_idx[0] = vecIndices[l_triA];
l_newQuad.s_idx[1] = vecIndices[l_triA + 1];
l_newQuad.s_idx[2] = vecIndices[l_triB + 2];
l_newQuad.s_idx[3] = vecIndices[l_triA + 2];
c_quads.push_back(l_newQuad);
}
}
int l_totalMerges = 0;
int l_passMerges = 0;
do{
l_passMerges = DoCoplanarMerge();
l_totalMerges += l_passMerges;
} while(l_passMerges);
PrepareOptimizedDisplayList();
}
int PolyvoxModel::DoCoplanarMerge(void){
const vector<PolyVox::PositionMaterialNormal>& vecVertices = c_surfaceMesh->getVertices();
// MERGE ADYACENT QUADS
vector<Quad> l_quadsByPlane[6];
enum{
eUp, eDown, eLeft, eRight, eForward, eBackward, ePlaneCount
};
for (int l_quadWalk = 0; l_quadWalk < c_quads.size(); l_quadWalk++){
PolyVox::Vector3DFloat l_normal = vecVertices[c_quads[l_quadWalk].s_idx[0]].getNormal();
if (l_normal.getX() == 1) l_quadsByPlane[eRight].push_back(c_quads[l_quadWalk]);
else if (l_normal.getX() == -1) l_quadsByPlane[eLeft].push_back(c_quads[l_quadWalk]);
else if (l_normal.getY() == 1) l_quadsByPlane[eUp].push_back(c_quads[l_quadWalk]);
else if (l_normal.getY() == -1) l_quadsByPlane[eDown].push_back(c_quads[l_quadWalk]);
else if (l_normal.getZ() == 1) l_quadsByPlane[eForward].push_back(c_quads[l_quadWalk]);
else if (l_normal.getZ() == -1) l_quadsByPlane[eBackward].push_back(c_quads[l_quadWalk]);
}
c_quads.clear();
// CHECK IF ANY TWO QUADS SHARE TWO VERTICES, MERGE THEM!
int l_mergedQuads = 0;
for (int l_planeWalk = 0; l_planeWalk < ePlaneCount; l_planeWalk++){
bool* l_alreadyMerged = new bool[l_quadsByPlane[l_planeWalk].size()];
memset(l_alreadyMerged, 0, l_quadsByPlane[l_planeWalk].size());
// MERGE AND PUSH ADJACENT QUADS
for (int l_currentQuadWalk = 0; l_currentQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_currentQuadWalk++){
if (l_alreadyMerged[l_currentQuadWalk]) continue;
Quad l_currentQuad = l_quadsByPlane[l_planeWalk][l_currentQuadWalk];
PolyVox::Vector3DFloat l_currentPos[4];
for (int l_vWalk = 0; l_vWalk < 4; l_vWalk++){
l_currentPos[l_vWalk] = vecVertices[l_currentQuad.s_idx[l_vWalk]].getPosition();
}
for (int l_compareQuadWalk = 0; l_compareQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_compareQuadWalk++){
if (l_currentQuadWalk == l_compareQuadWalk) continue;
if (l_alreadyMerged[l_currentQuadWalk]) break;
if (l_alreadyMerged[l_compareQuadWalk]) continue;
Quad l_compareQuad = l_quadsByPlane[l_planeWalk][l_compareQuadWalk];
PolyVox::Vector3DFloat l_comparePos[4];
for (int l_vWalk = 0; l_vWalk < 4; l_vWalk++){
l_comparePos[l_vWalk] = vecVertices[l_compareQuad.s_idx[l_vWalk]].getPosition();
}
if ((l_currentPos[2] == l_comparePos[1]) &&
(l_currentPos[3] == l_comparePos[0])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_currentQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_currentQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_compareQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_compareQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[1] == l_comparePos[0]) &&
(l_currentPos[2] == l_comparePos[3])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_currentQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_compareQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_compareQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_currentQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[0] == l_comparePos[3]) &&
(l_currentPos[1] == l_comparePos[2])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_compareQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_compareQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_currentQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_currentQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
else if ((l_currentPos[0] == l_comparePos[1]) &&
(l_currentPos[3] == l_comparePos[2])){
Quad l_mergedQuad;
l_mergedQuad.s_idx[0] = l_compareQuad.s_idx[0];
l_mergedQuad.s_idx[1] = l_currentQuad.s_idx[1];
l_mergedQuad.s_idx[2] = l_currentQuad.s_idx[2];
l_mergedQuad.s_idx[3] = l_compareQuad.s_idx[3];
c_quads.push_back(l_mergedQuad);
l_alreadyMerged[l_currentQuadWalk] = true;
l_alreadyMerged[l_compareQuadWalk] = true;
}
}
}
// PUSH LONELY QUADS
for (int l_currentQuadWalk = 0; l_currentQuadWalk < l_quadsByPlane[l_planeWalk].size(); l_currentQuadWalk++){
if (!l_alreadyMerged[l_currentQuadWalk]){
c_quads.push_back(l_quadsByPlane[l_planeWalk][l_currentQuadWalk]);
}
else{
l_mergedQuads++;
}
}
delete[] l_alreadyMerged;
}
return l_mergedQuads;
}
